The Data
Spotify’s extended streaming history goes back to your first play. Mine starts in 2012 — 10,133 hours, 147,594 streams, 15,748 unique artists across 14 years. 422 continuous days of listening. Here’s what the data says about who I am.
Each record has a timestamp, play duration, track URI, skip flag, shuffle flag, platform, and whether it was offline. It’s enough to reconstruct not just what I listened to but how I listened.
What I Built
A Python + DuckDB analysis pipeline that ingests all the raw JSON files, deduplicates, cleans edge cases, and outputs a set of explorable views.
Key Findings
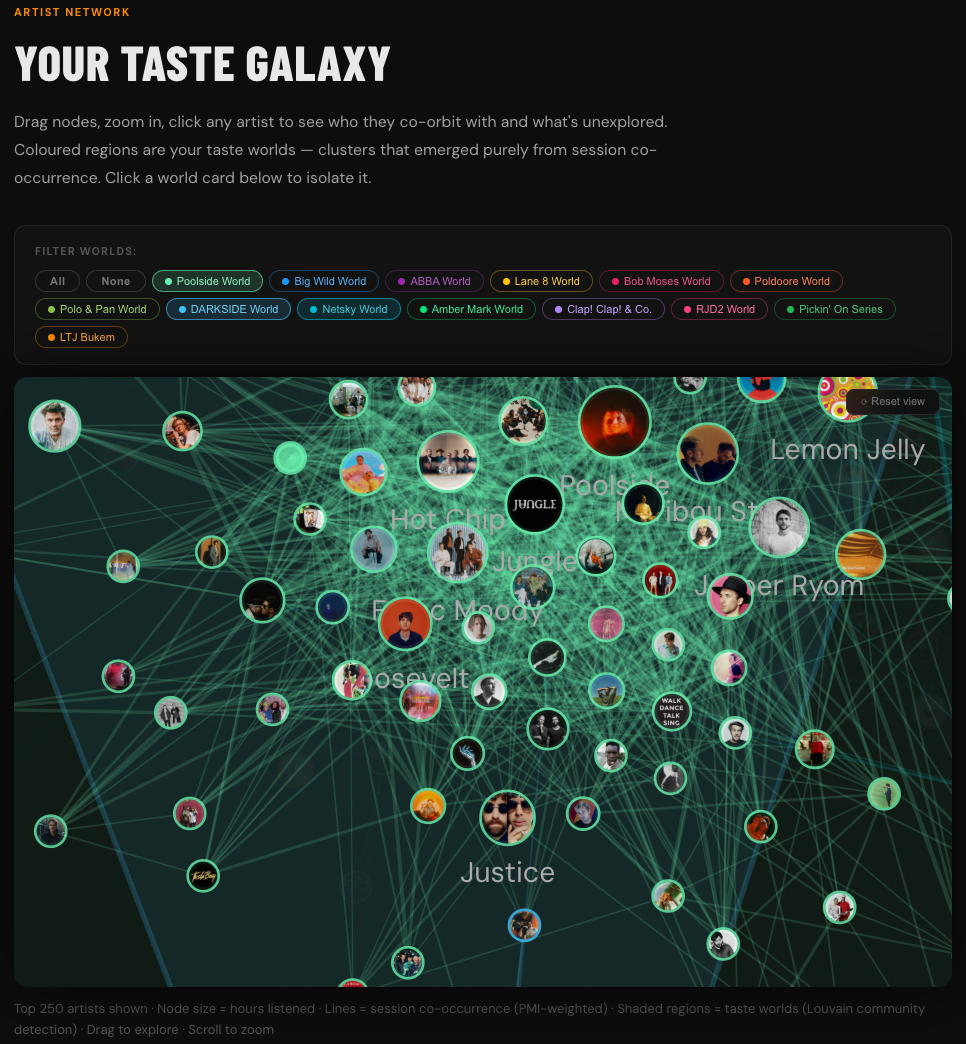
Top artist all-time: Mac Miller — by total minutes, by years present, by genre diversity.
Skip rate as signal: Songs I’ve never skipped once in 500+ plays are a fundamentally different kind of favorite than songs I’ve played 1,000 times but skipped 40% of the time. The “never-skip” list is the real canon.
Obsession cycles: I listen in phases. There’s a clear pattern of 6–8 week immersions into a single artist, followed by a reset. I can trace every relationship, job change, and major life event to a soundtrack change.
Listening by platform: Desktop vs. mobile vs. offline reveal different moods. Offline listening is almost always music I trust. Desktop listening skews to new exploration.
Discovery vs. catalog ratio: The share of first-time listens has dropped steadily since 2021 — I’m settling into a catalog instead of exploring. Concerning.
Tech Stack
- Python 3.9 — ingestion, cleaning, analysis
- DuckDB 1.4.4 — in-process analytics, fast joins across 67K records
- pandas — dataframe manipulation
- matplotlib + seaborn — chart generation
- Parquet — processed data persistence
The Hard Parts
Deduplication: Spotify double-logs plays that span offline/online sync transitions. Same track, same timestamp, different offline_timestamp. Deduplicated on (ts, track_uri, ms_played).
Track identity: The same song re-released on three different albums has three different URIs. Fell back to (artist_name, track_name) grouping for anything where URI-level precision caused fragmentation.
Minimum play threshold: 30 seconds. Below that it’s a skip regardless of what the reason_end field says.
Podcast contamination: All podcast and audiobook entries have null track fields. Filtered out for music analysis, kept separate for potential future work.
Concert Connection
The concert history analysis (concerts →) used the same Spotify data as one of three corroboration sources — scrobble timestamps verified against Google Calendar events and email receipts to reconstruct 178 live shows since 2007.